Beviset Chi kvadrat eller chi-firkant (χto, hvor χ er den greske bokstaven kalt "chi") brukes til å bestemme oppførselen til en bestemt variabel, og også når du vil vite om to eller flere variabler er statistisk uavhengige.
For å kontrollere oppførselen til en variabel, kalles testen som skal utføres chi kvadrat test av passform. For å finne ut om to eller flere variabler er statistisk uavhengige, kalles testen chi firkant av uavhengighet, også kalt beredskap.
Disse testene er en del av statistisk beslutningsteori, der en populasjon blir studert og det blir tatt beslutninger om den, og analyserer en eller flere prøver som er tatt fra den. Dette krever å gjøre visse antagelser om variablene, kalt hypotese, som kan eller ikke kan være sant.
Det er noen tester for å kontrastere disse antagelsene og bestemme hvilke som er gyldige, innenfor en viss tillitsmargin, inkludert chi-kvadrat-testen, som kan brukes til å sammenligne to og flere populasjoner..
Som vi vil se, blir to typer hypoteser vanligvis reist om noen populasjonsparametere i to prøver: nullhypotesen, kalt Heller (prøvene er uavhengige), og den alternative hypotesen, betegnet som H1, (prøvene er korrelert) som er motsatt av det.
Artikkelindeks
Chi-kvadrat-testen brukes på variabler som beskriver kvaliteter, som kjønn, sivilstand, blodgruppe, øyenfarge og preferanser av forskjellige typer.
Testen er ment når du vil:
-Kontrollere om en distribusjon er hensiktsmessig for å beskrive en variabel, som kalles godhet av passform. Ved å bruke chi-kvadrat-testen er det mulig å vite om det er signifikante forskjeller mellom den valgte teoretiske fordelingen og den observerte frekvensfordelingen..
-Vet om to variabler X og Y er uavhengige fra det statistiske synspunktet. Dette er kjent som uavhengighetstest.
Siden den brukes på kvalitative eller kategoriske variabler, brukes chi-square-testen mye i samfunnsvitenskap, ledelse og medisin..
Det er to viktige krav for å bruke det riktig:
-Dataene må grupperes i frekvenser.
-Prøven må være stor nok til at kikvadratfordelingen er gyldig, ellers er verdien overvurdert og fører til avvisning av nullhypotesen når det ikke skulle være tilfelle..
Den generelle regelen er at hvis en frekvens med en verdi mindre enn 5 vises i de grupperte dataene, blir den ikke brukt. Hvis det er mer enn en frekvens mindre enn 5, må de kombineres til en for å oppnå en frekvens med en numerisk verdi større enn 5.
χto det er en kontinuerlig fordeling av sannsynligheter. Egentlig er det forskjellige kurver, avhengig av en parameter k kalt grader av frihet av den tilfeldige variabelen.
Dens egenskaper er:
-Arealet under kurven er lik 1.
-Verdiene til χto de er positive.
-Fordelingen er asymmetrisk, det vil si at den har en skjevhet.
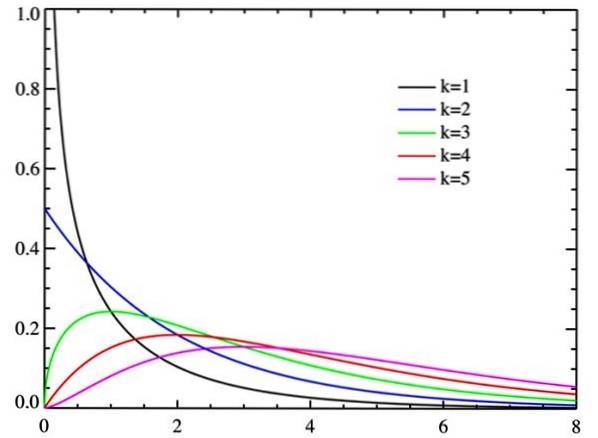
Når gradene av frihet øker, har chi-kvadratfordelingen en tendens til normalitet, som det fremgår av figuren.
For en gitt fordeling bestemmes frihetsgraden gjennom beredskapstabell, som er tabellen der de observerte frekvensene til variablene blir registrert.
Hvis et bord har F rader og c kolonnene, verdien av k Det er:
k = (f - 1) ⋅ (c - 1)
Når chi-kvadrat-testen er i form, formuleres følgende hypoteser:
-Heller: variabelen X har en sannsynlighetsfordeling f (x) med de spesifikke parametrene y1, Yto…, Ys
-H1: X har en annen sannsynlighetsfordeling.
Sannsynlighetsfordelingen antatt i nullhypotesen kan for eksempel være den kjente normalfordelingen, og parametrene vil være gjennomsnittet μ og standardavviket σ.
I tillegg blir nullhypotesen evaluert med et visst nivå av betydning, det vil si et mål på feilen som vil bli begått når man avviser at den er sann..
Vanligvis er dette nivået satt til 1%, 5% eller 10%, og jo lavere det er, desto mer pålitelig blir testresultatet..
Og hvis chi-kvadrat-testen av beredskap blir brukt, som, som vi har sagt, tjener til å verifisere uavhengigheten mellom to variabler X og Y, er hypotesene:
-Heller: variablene X og Y er uavhengige.
-H1: X og Y er avhengige.
Igjen er det nødvendig å spesifisere et nivå av betydning for å kjenne til feilmål når du tar avgjørelsen..
Statistikken for chi kvadrat beregnes som følger:
Summasjonen utføres fra første klasse i = 1 til den siste, som er i = k.
Hva mer:
-Feller er en observert frekvens (kommer fra innhentede data).
-Fog er forventet eller teoretisk frekvens (må beregnes ut fra dataene).
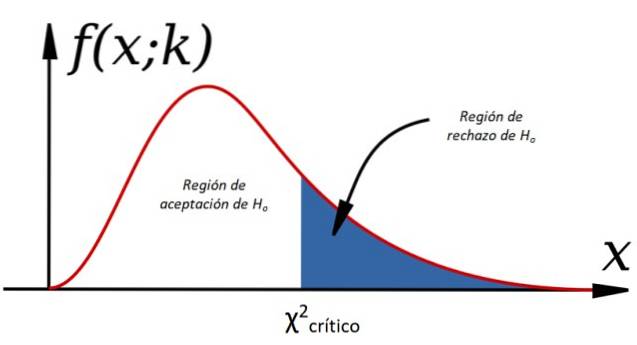
For å akseptere eller avvise nullhypotesen, beregner vi χto for de observerte dataene og sammenlignet med en verdi som kalles kritisk chi-firkant, som avhenger av gradene av frihet k og nivået av betydning α:
χtokritisk = χtok, α
Hvis vi for eksempel ønsker å utføre testen med et signifikansnivå på 1%, så er α = 0,01, hvis det kommer til å være med 5% så er α = 0,05 og så videre. Vi definerer p, parameteren for fordelingen, som:
p = 1 - α
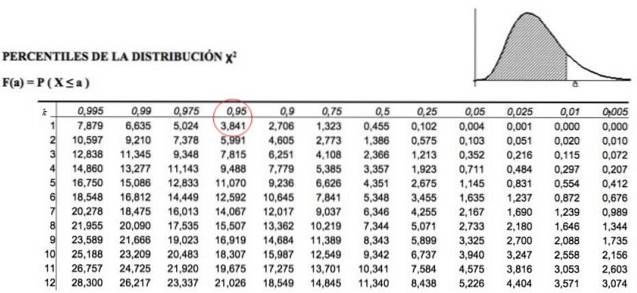
Disse kritiske chi-kvadratverdiene bestemmes av tabeller som inneholder den kumulative arealverdien. For eksempel, for k = 1, som representerer 1 frihetsgrad og α = 0,05, som tilsvarer p = 1- 0,05 = 0,95, verdien av χto er 3,841.
Kriteriet for å akseptere Heller Det er:
-Ja χto < χtokritisk H akseptereseller, ellers blir den avvist (se figur 1).
I den følgende applikasjonen vil chi kvadrat test brukes som en test av uavhengighet.
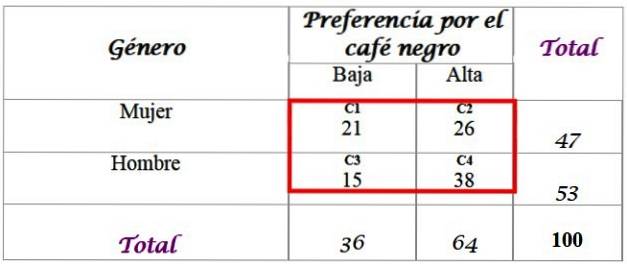
Anta at forskerne vil vite om preferansen for svart kaffe er relatert til kjønnet til personen, og spesifiser svaret med et signifikansnivå på α = 0,05.
For dette er et utvalg på 100 personer intervjuet og deres svar tilgjengelig:
Sett hypotesene:
-Heller: kjønn og preferanse for svart kaffe er uavhengig.
-H1: smaken for svart kaffe er relatert til kjønnet til personen.
Beregn forventede frekvenser for fordelingen, som totalene som er lagt til i den siste raden og i høyre kolonne i tabellen kreves. Hver celle i den røde boksen har en forventet verdi Fog, som beregnes ved å multiplisere totalen for raden din F med summen av kolonnen C, delt på totalen av prøven N:
Fog = (F x C) / N
Resultatene er som følger for hver celle:
-C1: (36 x 47) / 100 = 16,92
-C2: (64 x 47) / 100 = 30,08
-C3: (36 x 53) / 100 = 19.08
-C4: (64 x 53) / 100 = 33,92
Deretter må chi-kvadratstatistikken beregnes for denne fordelingen, i henhold til den gitte formelen:
Bestem χtokritisk, vel vitende om at de registrerte dataene er i f = 2 rader og c = 2 kolonner, derfor er antall frihetsgrader:
k = (2-1) ⋅ (2-1) = 1.
Hvilket betyr at vi må se i verdien i tabellen ovenfortok, α = χto1; 0,05 , som er:
χtokritisk = 3,841
Sammenlign verdiene og bestem:
χto = 2.9005
χtokritisk = 3,841
Siden χto < χtokritisk nullhypotesen aksepteres og det konkluderes med at preferansen for svart kaffe ikke er knyttet til kjønnet til personen, med et signifikansnivå på 5%.



Ingen har kommentert denne artikkelen ennå.