De grader av frihet i statistikk er de antall uavhengige komponenter i en tilfeldig vektor. Hvis vektoren har n komponenter og det er s lineære ligninger som relaterer komponentene deres, deretter grad av frihet er n-p.
Konseptet av grader av frihet Det vises også i teoretisk mekanikk, hvor de tilsvarer omtrent dimensjonen til rommet der partikkelen beveger seg, minus antall bindinger..
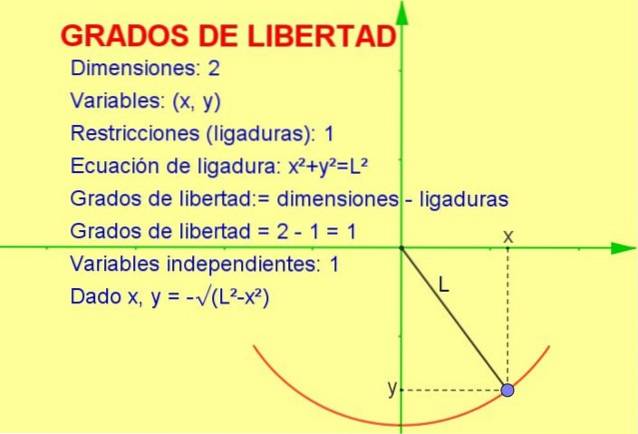
Denne artikkelen vil diskutere begrepet frihetsgrader brukt på statistikk, men et mekanisk eksempel er lettere å visualisere i geometrisk form.
Artikkelindeks
Avhengig av konteksten den brukes i, kan måten å beregne antall frihetsgrader variere på, men den underliggende ideen er alltid den samme: totale dimensjoner minus antall begrensninger.
La oss vurdere en oscillerende partikkel bundet til en streng (en pendel) som beveger seg i det vertikale x-y-planet (2 dimensjoner). Imidlertid blir partikkelen tvunget til å bevege seg på radiusens omkrets lik akkordlengden.
Siden partikkelen bare kan bevege seg på den kurven, blir antallet grader av frihet er 1. Dette kan sees i figur 1.
Måten å beregne antall frihetsgrader på er å ta forskjellen på antall dimensjoner minus antall begrensninger:
frihetsgrader: = 2 (dimensjoner) - 1 (ligatur) = 1
En annen forklaring som gjør at vi kan komme til resultatet er følgende:
-Vi vet at posisjonen i to dimensjoner er representert med et koordinatpunkt (x, y).
-Men siden poenget må tilfredsstille ligningen til omkretsen (xto + Yto = Lto) for en gitt verdi av variabelen x, bestemmes variabelen y av ligningen eller begrensningen.
Dermed er bare en av variablene uavhengig, og systemet har en (1) grad av frihet.
Anta vektoren for å illustrere hva konseptet betyr
x = (x1, xto,..., xn)
Hva representerer utvalget av n normalt distribuerte tilfeldige verdier. I dette tilfellet den tilfeldige vektoren x ha n uavhengige komponenter og derfor sies det at x ha n grader av frihet.
La oss nå bygge vektoren r av avfall
r = (x1 -
Hvor
Så summen
(x1 -
Det er en ligning som representerer en begrensning (eller binding) til elementene i vektoren r av restene, siden hvis n-1 komponenter av vektoren er kjent r, begrensningsligningen bestemmer den ukjente komponenten.
Derfor vektoren r av dimensjon n med begrensningen:
∑ (xJeg -
Ha (n - 1) frihetsgrader.
Igjen brukes det at beregningen av antall frihetsgrader er:
frihetsgrader: = n (dimensjoner) - 1 (begrensninger) = n-1
Avviket sto er definert som gjennomsnittet av kvadratet av avvikene (eller restene) av utvalget av n data:
sto = (r•r) / (n-1)
hvor r er vektoren til restene r = (x1 -
sto = ∑ (xJeg -
I alle fall skal det bemerkes at når man beregner gjennomsnittet av kvadratet til restene, er det delt med (n-1) og ikke med n, siden som diskutert i forrige avsnitt, antall frihetsgrader for vektor r er (n-1).
Hvis for beregningen av variansen ble delt med n i stedet for (n-1), vil resultatet ha en skjevhet som er veldig viktig for verdiene på n under 50 år.
I litteraturen vises variansformelen også med divisoren n i stedet for (n-1), når det gjelder variansen til en populasjon.
Men settet med den tilfeldige variabelen til restene, representert av vektoren r, Selv om den har dimensjon n, har den bare (n-1) frihetsgrader. Imidlertid, hvis antall data er stort nok (n> 500), konvergerer begge formlene til det samme resultatet.
Kalkulatorer og regneark gir begge versjoner av variansen og standardavviket (som er kvadratroten til variansen).
Vår anbefaling, med tanke på analysen som presenteres her, er å alltid velge versjonen med (n-1) hver gang det kreves å beregne avvik eller standardavvik, for å unngå partiske resultater..
Noen sannsynlighetsfordelinger i kontinuerlig tilfeldig variabel avhenger av en parameter som heter grad av frihet, er tilfellet med Chi-kvadratfordelingen (χto).
Navnet på denne parameteren kommer nøyaktig fra frihetsgraden til den underliggende tilfeldige vektoren som denne fordelingen gjelder for.
Anta at vi har g populasjoner, hvorfra det tas prøver av størrelse n:
X1 = (x11, x1to,... X1n)
X2 = (x21, x2to,... X2n)
... .
Xj = (xj1, xjto,... Xjn)
... .
Xg = (xg1, xgto,... Xgn)
En befolkning j hva har gjennomsnittet
Den standardiserte eller normaliserte variabelen zjJeg er definert som:
zjJeg = (xjJeg -
Og vektoren Zj er definert slik:
Zj = (zj1, zjto,..., zjJeg,..., zjn) og følger den standardiserte normalfordelingen N (0,1).
Så variabelen:
Spørsmål = ((z11 ^ 2 + z21^ 2 +…. + zg1^ 2),…., (Z1n^ 2 + z2n^ 2 +…. + zgn^ 2))
følg fordelingen χto(g) kalte chi kvadratfordeling med grad av frihet g.
Når du vil teste hypoteser basert på et bestemt sett med tilfeldige data, må du vite antall frihetsgrader g for å kunne anvende Chi square testen.
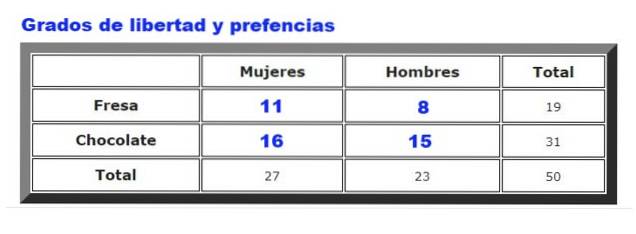
Som et eksempel, vil dataene som er samlet inn om preferansene til sjokolade eller jordbæris blant menn og kvinner i en bestemt iskrem, bli analysert. Frekvensen som menn og kvinner velger jordbær eller sjokolade er oppsummert i figur 2.
Først beregnes tabellen over forventede frekvenser, som blir utarbeidet ved å multiplisere totalt antall rader for han totalt kolonner, delt på totale data. Resultatet er vist i følgende figur:

Så fortsetter vi med å beregne Chi-firkanten (fra dataene) ved hjelp av følgende formel:
χto = ∑ (F.eller - Fog)to / Fog
Hvor Feller er de observerte frekvensene (figur 2) og Fog er forventede frekvenser (figur 3). Summasjonen går over alle radene og kolonnene, som i vårt eksempel gir fire termer.
Etter å ha gjort operasjonene får du:
χto = 0,2043.
Nå er det nødvendig å sammenligne med den teoretiske Chi-firkanten, som avhenger av antall frihetsgrader g.
I vårt tilfelle bestemmes dette tallet som følger:
g = (# rader - 1) (# kolonner - 1) = (2 - 1) (2 - 1) = 1 * 1 = 1.
Det viser seg at antall frihetsgrader g i dette eksemplet er 1.
Hvis du vil sjekke eller avvise nullhypotesen (H0: det er ingen sammenheng mellom SMAK og KJØNN) med et signifikansnivå på 1%, beregnes den teoretiske Chi-kvadratverdien med frihetsgrad g = 1.
Verdien søkes som gjør at den akkumulerte frekvensen (1 - 0.01) = 0.99, det vil si 99%. Denne verdien (som kan fås fra tabellene) er 6.636.
Da den teoretiske Chi overstiger den beregnede, blir nullhypotesen bekreftet.
Det vil si med dataene som er samlet inn, Ikke observert forholdet mellom variablene TASTE og GENDER.



Ingen har kommentert denne artikkelen ennå.