
De inferensiell statistikk eller deduktiv statistikk er en som trekker ut karakteristikkene til en populasjon fra prøver tatt fra den, gjennom en rekke analyseteknikker. Med den innhentede informasjonen utvikles modeller som deretter tillater spådommer om atferden til nevnte befolkning..
Av denne grunn har inferensiell statistikk blitt den viktigste vitenskapen i å tilby støtten og instrumentene som utallige fagområder krever når du tar beslutninger..

Fysikk, kjemi, biologi, ingeniørfag og samfunnsvitenskap drar kontinuerlig fordel av disse verktøyene når de lager modeller og designer og implementerer eksperimenter..
Artikkelindeks
Statistikk oppsto i eldgamle tider på grunn av behovet for mennesker til å organisere ting og optimalisere ressursene. Før oppfinnelsen av skrivingen ble det ført oversikt over antall personer og tilgjengelig husdyr ved hjelp av symboler som var inngravert i stein..
Senere etterlot de kinesiske, babyloniske og egyptiske herskerne data om mengden av avlinger og antall innbyggere, gravert på leirtavler, søyler og monumenter..
Da Roma utøvde sitt herredømme i Middelhavet, var det vanlig at myndighetene gjennomførte folketellinger hvert femte år. Faktisk kommer ordet "statistikk" fra det italienske ordet statista, hva betyr det å uttrykke.
Samtidig holdt de store pre-colombianske imperiene i Amerika også lignende poster.
I løpet av middelalderen registrerte regjeringene i Europa, så vel som kirken, eierskap til land. Så gjorde de det samme med fødsler, dåp, ekteskap og dødsfall.
Den engelske statistikeren John Graunt (1620-1674) var den første som spådde basert på slike lister, for eksempel hvor mange mennesker som kunne dø av visse sykdommer og den estimerte andelen mannlige og kvinnelige fødsler. Av denne grunn regnes han som far for demografien..
Senere, med fremveksten av sannsynlighetsteorien, opphørte statistikken å være bare en samling organisasjonsteknikker og oppnådde et uventet omfang som en prediktiv vitenskap..
Ekspertene kunne således begynne å utvikle modeller for oppførselen til befolkningen og sammen med dem utlede hvilke ting som kan skje med mennesker, gjenstander og til og med ideer..

Nedenfor har vi de mest relevante egenskapene til denne grenen av statistikk:
- Inferensiell statistikk studerer en populasjon som tar et representativt utvalg fra den.
- Valget av prøven utføres gjennom forskjellige prosedyrer, den mest passende er de som velger komponentene tilfeldig. Dermed har ethvert element i befolkningen den samme sannsynligheten for å bli valgt, og dermed unngås uønskede skjevheter..
- For å organisere den innsamlede informasjonen, benyttes beskrivende statistikk.
- Statistiske variabler beregnes på utvalget som brukes til å estimere egenskapene til befolkningen..
- Inferensiell eller deduktiv statistikk bruker sannsynlighetsteori til å studere tilfeldige hendelser, det vil si de som oppstår tilfeldig. Hver hendelse er tildelt en viss sannsynlighet for forekomst.
- Den konstruerer hypoteser - antagelser - om parametrene til befolkningen og kontrasterer dem, for å finne ut om de er riktige eller ikke, og beregner også konfidensnivået til svaret, det vil si at det gir en feilmargin. Den første prosedyren kalles hypotesetesting, mens feilmarginen er konfidensintervall.

Å studere en befolkning i sin helhet kan kreve mye ressurser i penger, tid og krefter. Det er å foretrekke å ta representative prøver som er mye mer håndterbare, samle inn data fra dem og lage hypoteser eller antagelser om prøveatferd..
Når hypotesene er etablert og gyldigheten deres er testet, utvides resultatene til befolkningen og brukes til å ta beslutninger..
De hjelper også med å lage modeller av den befolkningen, for å lage fremskrivninger for fremtiden. Derfor er inferensiell statistikk en veldig nyttig vitenskap for:
Dette er ideelle bruksområder, siden statistiske teknikker brukes med ideen om å etablere ulike modeller for menneskelig atferd. Noe som a priori er ganske komplisert, siden mange variabler griper inn.
I politikken brukes det mye ved valgtid å kjenne velgernes valgtendens, på denne måten utformer partiene strategier.
Inferensiell statistikk metoder er mye brukt i ingeniørfag, de viktigste applikasjonene er kvalitetskontroll og prosessoptimalisering, for eksempel å forbedre tidene når du utfører oppgaver, samt forhindre arbeidsulykker..
Med deduktive metoder kan du utføre anslag om driften av et selskap, forventet salgsnivå, samt hjelp til å ta beslutninger.
For eksempel kan deres teknikker brukes til å estimere hva som vil være kjøpernes reaksjon på et nytt produkt, som snart skal lanseres på markedet..
Det tjener også til å evaluere hvordan endringer i folks forbruksvaner er, gitt viktige hendelser, som COVID-epidemien..
Et enkelt deduktivt statistikkproblem er følgende: en matematikklærer har ansvaret for 5 seksjoner av elementær algebra på et universitet og bestemmer seg for å bruke gjennomsnittlig karakter på bare én av seksjonene for å estimere gjennomsnittet av alle.

En annen mulighet er å ta et utvalg fra hver seksjon, studere egenskapene og utvide resultatene til alle seksjoner..
Lederen for en damebutikk vil vite hvor mye en viss bluse vil selge i sommersesongen. For å gjøre dette analyserer den salget av plagget i løpet av de to første ukene av sesongen og bestemmer dermed trenden..
Det er flere nøkkelbegreper, inkludert de som kommer fra sannsynlighetsteori, som du må være tydelig på for å forstå det fulle omfanget av disse teknikkene. Noen, som en populasjon og et utvalg, har vi allerede nevnt i hele teksten.
En hendelse eller hendelse er noe som skjer, og som kan ha flere resultater. Et eksempel på en hendelse kan være å snu en mynt, og det er to mulige utfall: hoder eller haler.
Det er settet med alle mulige resultater av en hendelse.
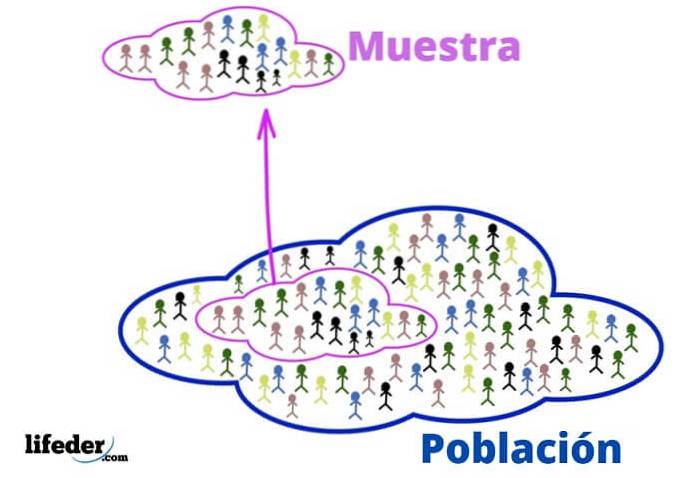
Befolkningen er det universet du vil studere. Det handler ikke nødvendigvis om mennesker eller levende vesener, siden befolkningen i statistikk kan bestå av objekter eller ideer.
Utvalget er for sin del en delmengde av populasjonen, nøye hentet fra den fordi den er representativ..
Det er settet med teknikker som et utvalg er valgt fra en gitt populasjon. Prøvetaking kan være tilfeldig hvis probabilistiske metoder brukes til å velge utvalget, eller ikke-probabilistisk, hvis analytikeren har sine egne utvalgskriterier, ifølge hans erfaring..
Verdisett som kan ha karakteristikkene til befolkningen. De er klassifisert på forskjellige måter, for eksempel kan de være diskrete eller kontinuerlige. I tillegg til å ta hensyn til deres natur kan de være kvalitative eller kvantitative..
Sannsynlighetsfunksjoner som beskriver oppførselen til et stort antall systemer og situasjoner observert i naturen. Den mest kjente er den Gaussiske eller Gaussiske bjellefordelingen og binomialfordelingen.
Estimeringsteorien fastslår at det er en sammenheng mellom verdiene til befolkningen og verdiene til utvalget tatt fra denne populasjonen. De parametere er egenskapene til befolkningen som vi ikke kjenner, men ønsker å estimere: for eksempel middel- og standardavvik.
For deres del statistikk er egenskapene til prøven, for eksempel dens gjennomsnitt og standardavvik.
Anta som et eksempel at befolkningen består av alle ungdommer mellom 17 og 30 år i et samfunn, og vi vil vite andelen av de som nå er i høyere utdanning. Dette vil være populasjonsparameteren å bestemme.
For å estimere det velges et tilfeldig utvalg på 50 unge, og andelen av dem som studerer ved et universitet eller institutt for høyere utdanning blir beregnet. Denne andelen er statistikken.
Hvis det etter studien er fastslått at 63% av de 50 ungdommene er i høyere utdanning, er dette populasjonsestimatet, laget fra utvalget.
Dette er bare ett eksempel på hva inferensiell statistikk kan gjøre. Det er kjent som estimering, men det er også teknikker for å forutsi statistiske variabler, samt for å ta beslutninger.
Det er en formodning om verdien av middelverdien og standardavviket til noen karakteristika for befolkningen. Med mindre befolkningen er fullstendig undersøkt, er dette ukjente verdier.
Er antagelsene om populasjonsparametrene gyldige? For å finne ut er det verifisert om resultatene fra prøven støtter dem eller ikke, så det er nødvendig å utforme hypotesetester.
Dette er de generelle trinnene for å utføre en:
Identifiser typen fordeling som befolkningen forventes å følge.
Angi to hypoteser, betegnet som Heller og H1. Den første er nullhypotesen der vi antar at parameteren har en viss verdi. Det andre er den alternative hypotesen som antar en annen verdi enn nullhypotesen. Hvis dette avvises, aksepteres den alternative hypotesen.
Sett en akseptabel margin for forskjellen mellom parameteren og statistikken. Disse vil sjelden vise seg å være identiske, selv om de forventes å være veldig nærme..
Foreslå et kriterium for å godta eller avvise nullhypotesen. For dette brukes en teststatistikk, som kan være gjennomsnittet. Hvis middelverdien er innenfor visse grenser, aksepteres nullhypotesen, ellers avvises den.
Som et siste trinn avgjøres det hvorvidt nullhypotesen skal aksepteres..
Grener av statistikk.
Statistiske variabler.
Befolkning og prøve.
Beskrivende statistikk.


Ingen har kommentert denne artikkelen ennå.