De Absolutt frecuency Det er definert som antall ganger de samme dataene gjentas innenfor settet av observasjoner av en numerisk variabel. Summen av alle de absolutte frekvensene tilsvarer summen av dataene.
Når du har mange verdier av en statistisk variabel, er det praktisk å organisere dem på riktig måte for å hente ut informasjon om dens oppførsel. Slik informasjon gis av målingene av sentral tendens og målingene av spredning..
I beregningene av disse tiltakene blir dataene representert gjennom frekvensen som de vises i alle observasjonene..
Følgende eksempel viser hvor avslørende den absolutte frekvensen til hvert stykke data er. I løpet av første halvdel av mai var dette de mest solgte cocktailkjolestørrelsene fra en kjent dameklærbutikk:
8; 10; 8; 4; 6; 10; 12; 14; 12; 16; 8; 10; 10; 12; 6; 6; 4; 8; 12; 12; 14; 16; 18; 12; 14; 6; 4; 10; 10; 18
Hvor mange kjoler selges i en bestemt størrelse, for eksempel størrelse 10? Eiere er interessert i å vite å bestille.
Å bestille data gjør det lettere å telle, det er nøyaktig 30 observasjoner totalt, som bestilt fra minste størrelse til den største er som følger:
4; 4; 4; 6; 6; 6; 6; 8; 8; 8; 8; 10; 10; 10; 10; 10; 10; 12; 12; 12; 12; 12; 12; 14; 14; 14; 16; 16; 18; 18
Og nå er det tydelig at størrelse 10 gjentas 6 ganger, derfor er dens absolutte frekvens lik 6. Den samme prosedyren utføres for å finne ut den absolutte frekvensen til de gjenværende størrelsene..
Artikkelindeks
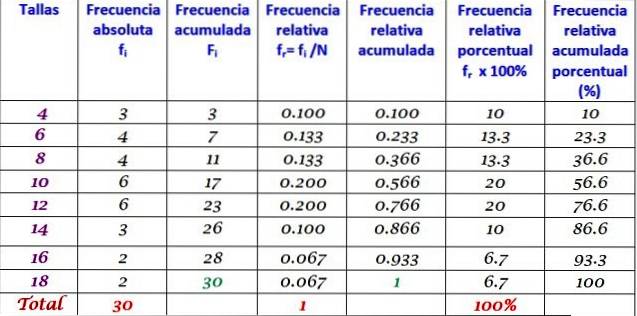
Den absolutte frekvensen, betegnet som fJeg, er lik antall ganger en bestemt verdi XJeg er innenfor gruppen observasjoner.
Forutsatt at den totale observasjonen er N-verdier, må summen av alle de absolutte frekvensene være lik dette tallet:
∑fJeg = f1 + Fto + F3 +... fn = N
Hvis hver verdi av fJeg delt på totalt antall data N, har vi relativ frekvens Fr av X-verdienJeg:
Fr = fJeg / N
Relative frekvenser er verdier mellom 0 og 1, fordi N alltid er større enn noen fJeg, men summen må være lik 1.
Multipliser hver verdi av f med 100r du har prosent relativ frekvens, hvis sum er 100%:
Prosentandel relativ frekvens = (fJeg / N) x 100%
Også viktig er Kumulativ frekvens FJeg opp til en viss observasjon, er dette summen av alle de absolutte frekvensene til og med nevnte observasjon:
FJeg = f1 + Fto + F3 +... fJeg
Hvis den akkumulerte frekvensen er delt på det totale antallet data N, har vi kumulativ relativ frekvens, multiplisert med 100 gir prosent kumulativ relativ frekvens.
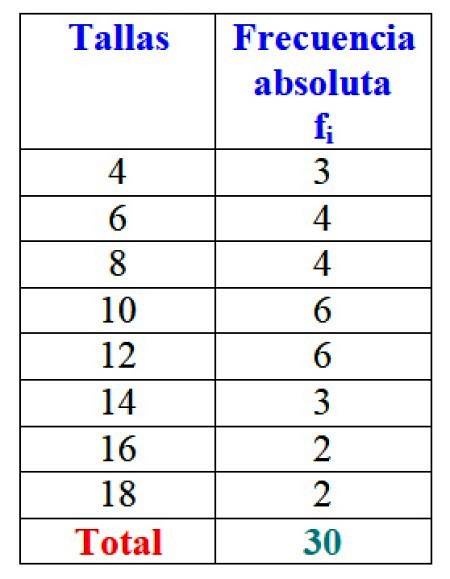
For å finne den absolutte frekvensen til en bestemt verdi som tilhører et datasett, er alle organisert fra laveste til høyeste, og antall ganger verdien vises vises telles.
I eksemplet på kjolestørrelser er den absolutte frekvensen for størrelse 4 3 kjoler, det vil si f1 = 3. For størrelse 6 ble det solgt 4 kjoler: fto = 4. I størrelse 8 ble det også solgt 4 kjoler, f3 = 4 og så videre.
De totale resultatene kan vises i en tabell som viser de absolutte frekvensene til hver enkelt:
Det er åpenbart fordelaktig å organisere informasjonen og kunne få tilgang til den på et øyeblikk, i stedet for å jobbe med individuelle data.
Viktig: Vær oppmerksom på at når du legger til alle verdiene i kolonne fJeg du får alltid det totale antallet data. Hvis ikke, må du sjekke regnskapet, siden det er en feil.
Ovenstående tabell kan utvides ved å legge til de andre frekvens typene i påfølgende kolonner til høyre:
Frekvensfordelingen er resultatet av å organisere dataene når det gjelder frekvenser. Når du arbeider med mange data, er det praktisk å gruppere dem i kategorier, intervaller eller klasser, hver med sine respektive frekvenser: absolutt, relativt, akkumulert og prosent..
Målet med å gjøre dem er å få lettere tilgang til informasjonen i dataene, samt å tolke dem ordentlig, noe som ikke er mulig når de presenteres i ingen rekkefølge..
I eksemplet med størrelser er ikke dataene gruppert, da de ikke er for mange størrelser og lett kan manipuleres og redegjøres for. Kvalitative variabler kan også bearbeides på denne måten, men når dataene er veldig mange, er det bedre å jobbe ved å gruppere dem i klasser.
For å gruppere dataene dine i klasser av samme størrelse, bør du vurdere følgende:
-Klassestørrelse, bredde eller bredde: er forskjellen mellom den høyeste verdien i klassen og den laveste.
Størrelsen på klassen avgjøres ved å dele rangeringen R med antall klasser som skal vurderes. Området er forskjellen mellom den maksimale verdien av dataene og den minste, slik:
Klassestørrelse = Rangering / Antall klasser.
-Klassegrense: intervall fra nedre grense til øvre grense i klassen.
-Klassemerke: er midtpunktet for intervallet, som anses å være representativt for klassen. Det beregnes med halvsummen av øvre og nedre grense for klassen.
-Antall klasser: Sturges formel kan brukes:
Antall klasser = 1 + 3 322 logg N
Hvor N er antall klasser. Siden det vanligvis er et desimaltall, avrundes det til neste heltall.
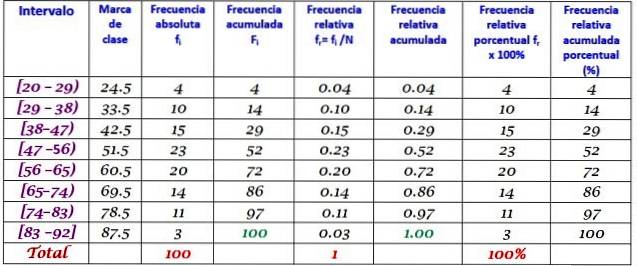
En maskin i en stor fabrikk er ute av drift på grunn av gjentatte feil. De påfølgende periodene av inaktivitet i minutter av maskinen er registrert nedenfor, med totalt 100 data:
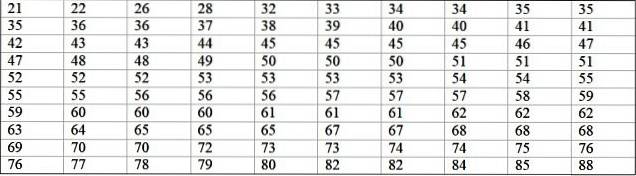
Først bestemmes antall klasser:
Antall klasser = 1 + 3,322 log N = 1 + 3,32 log 100 = 7,64 ≈ 8
Klassestørrelse = Rekkevidde / Antall klasser = (88-21) / 8 = 8.375
Det er også et desimaltall, så 9 tas som klassestørrelse.
Klassemerket er gjennomsnittet mellom øvre og nedre grense for klassen, for eksempel for klasse [20-29] er det et merke på:
Klassemerke = (29 + 20) / 2 = 24,5
Vi fortsetter på samme måte for å finne klassemerker for de gjenværende intervallene.
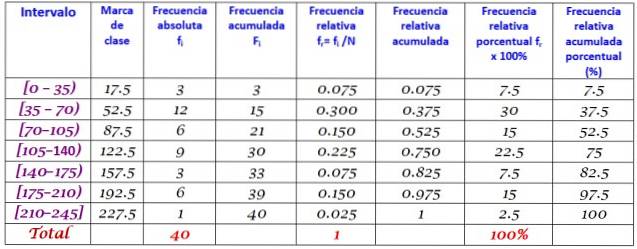
40 unge indikerte at tiden i minutter de brukte på internett sist søndag var følgende, bestilt i økende rekkefølge:
0; 12; tjue; 35; 35; 38; 40; Fire fem; 45, 45; 59; 55; 58; 65; 65; 70; 72; 90; 95; 100; 100; 110; 110; 110; 120; 125; 125; 130; 130; 130; 150; 160; 170; 175; 180; 185; 190; 195; 200; 220.
Det blir bedt om å konstruere frekvensfordelingen av disse dataene.
Området R for settet med N = 40 data er:
R = 220 - 0 = 220
Å bruke Sturges-formelen for å bestemme antall klasser gir følgende resultat:
Antall klasser = 1 + 3322 log N = 1 + 3,32 log 40 = 6,3
Siden det er en desimal, er det umiddelbare heltallet 7, derfor blir dataene gruppert i 7 klasser. Hver klasse har en bredde på:
Klassestørrelse = Rangering / Antall klasser = 220/7 = 31.4
En nær og rund verdi er 35, derfor velges en klassebredde på 35.
Klassemerker beregnes ved å beregne gjennomsnittet av de øvre og nedre grensene for hvert intervall, for eksempel for intervallet [0,35):
Klassemerke = (0 + 35) / 2 = 17,5
Fortsett på samme måte som de andre klassene.
Til slutt beregnes frekvensene i henhold til fremgangsmåten beskrevet ovenfor, noe som resulterer i følgende fordeling:



Ingen har kommentert denne artikkelen ennå.