EN empirisk regel Det er resultatet av praktisk erfaring og observasjon fra det virkelige liv. For eksempel er det mulig å vite hvilke fuglearter som kan observeres på bestemte steder hver gang på året, og fra den observasjonen kan en "regel" etableres som beskriver livssyklusen til disse fuglene.
I statistikk refererer den empiriske regelen til måten observasjoner er gruppert rundt en sentral verdi, gjennomsnittet eller gjennomsnittet, i enheter med standardavvik..

Anta at du har en gruppe mennesker med en gjennomsnittlig høyde på 1,62 meter og et standardavvik på 0,25 meter, så vil den empiriske regelen tillate deg å definere for eksempel hvor mange mennesker som vil være i et intervall på gjennomsnittet pluss eller minus en standardavvik?
I følge regelen er 68% av dataene mer eller mindre ett standardavvik fra gjennomsnittet, det vil si 68% av menneskene i gruppen vil ha en høyde mellom 1,37 (1,62-0,25) og 1,87 (1,62 + 0,25) meter.
Artikkelindeks
Den empiriske regelen er en generalisering av Tchebyshev-setningen og normalfordelingen.
Tchebyshevs teorem sier at: for en eller annen verdi av k> 1, er sannsynligheten for at en tilfeldig variabel faller mellom gjennomsnittet minus k ganger standardavviket, og gjennomsnittet pluss k ganger, er standardavviket større enn eller lik (1 - 1 / kto).
Fordelen med denne teoremet er at den gjelder diskrete eller kontinuerlige tilfeldige variabler med en hvilken som helst sannsynlighetsfordeling, men regelen definert fra den er ikke alltid veldig presis, siden den avhenger av symmetrien til fordelingen. Jo mer skjev fordelingen av den tilfeldige variabelen, jo mindre justert til regelen vil dens oppførsel være.
Den empiriske regelen definert fra denne teoremet er:
Hvis k = √2, sies det at 50% av dataene er i intervallet: [µ - √2 s, µ + √2 s]
Hvis k = 2, sies det at 75% av dataene er i intervallet: [µ - 2 s, µ + 2 s]
Hvis k = 3, sies det at 89% av dataene er i intervallet: [µ - 3 s, µ + 3 s]
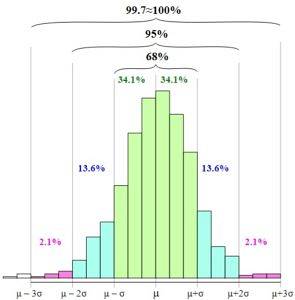
Normalfordelingen, eller Gaussian bell, gjør det mulig å etablere den empiriske regelen eller regel 68 - 95 - 99,7.
Regelen er basert på sannsynligheten for forekomst av en tilfeldig variabel i intervaller mellom gjennomsnittet minus ett, to eller tre standardavvik og gjennomsnittet pluss en, to eller tre standardavvik..
Den empiriske regelen definerer følgende intervaller:
68,27% av dataene er i intervallet: [µ - s, µ + s]
95,45% av dataene er i intervallet: [µ - 2s, µ + 2s]
99,73% av dataene er i intervallet: [µ - 3s, µ + 3s]
På figuren kan du se hvordan disse intervallene presenteres og forholdet mellom dem når du øker bredden på grafens basis.
Derfor definerer anvendelsen av den empiriske regelen i skala av en standard normalvariabel, z, følgende intervaller:
68,27% av dataene er i intervallet: [-1, 1]
95,45% av dataene er i intervallet: [-2, 2]
99,73% av dataene er i intervallet: [-3, 3]
Den empiriske regelen tillater forkortede beregninger når du arbeider med en normalfordeling.
Anta at en gruppe på 100 studenter har en gjennomsnittsalder på 23 år, med et standardavvik på 2 år. Hvilken informasjon tillater den empiriske regelen?
Å bruke den empiriske regelen innebærer å følge trinnene:
Siden gjennomsnittet er 23 og standardavviket er 2, er intervallene:
[µ - s, µ + s] = [23 - 2, 23 + 2] = [21, 25]
[µ - 2s, µ + 2s] = [23 - 2 (2), 23 + 2 (2)] = [19, 27]
[µ - 3s, µ + 3s] = [23 - 3 (2), 23 + 3 (2)] = [17, 29]
(100) * 68,27% = 68 studenter omtrent
(100) * 95,45% = 95 studenter omtrent
(100) * 99,73% = omtrent 100 studenter
Minst 68 studenter er mellom 21 og 25 år.
Minst 95 studenter er mellom 19 og 27 år.
Nesten 100 studenter er mellom 17 og 29 år.
Den empiriske regelen er en rask og praktisk måte å analysere statistiske data på, og blir mer og mer pålitelig når fordelingen nærmer seg symmetri.
Nytten avhenger av feltet det brukes i og spørsmålene som presenteres. Det er veldig nyttig å vite at forekomsten av verdier av tre standardavvik under eller over gjennomsnittet er nesten usannsynlig, selv for ikke-normale fordelingsvariabler, er minst 88,8% av tilfellene i intervallet tre sigma.
I samfunnsvitenskapen er et generelt avgjørende resultat intervallet for gjennomsnittet pluss eller minus to sigma (95%), mens i partikkelfysikk krever en ny effekt et fem sigma-intervall (99,99994%) for å bli betraktet som en oppdagelse..
I et naturreservat anslås det at det i gjennomsnitt er 16 000 kaniner med et standardavvik på 500 kaniner. Hvis fordelingen av variabelen "antall kaniner i reservatet" er ukjent, er det mulig å estimere sannsynligheten for at kaninpopulasjonen er mellom 15.000 og 17.000 kaniner?
Intervallet kan presenteres i disse vilkårene:
15000 = 16000 - 1000 = 16000 - 2 (500) = µ - 2 s
17000 = 16000 + 1000 = 16000 + 2 (500) = µ + 2 s
Derfor: [15000, 17000] = [µ - 2 s, µ + 2 s]
Ved å anvende Tchebyshevs teorem er det en sannsynlighet på minst 0,75 at kaninbestanden i naturreservatet er mellom 15.000 og 17.000 kaniner..
Gjennomsnittsvekten til ett år gamle barn i et land fordeles normalt med et gjennomsnitt på 10 kilo og et standardavvik på omtrent 1 kilo.
a) Beregn prosentandelen ett år gamle barn i landet som har en gjennomsnittsvekt mellom 8 og 12 kilo.
8 = 10 - 2 = 10 - 2 (1) = µ - 2 s
12 = 10 + 2 = 10 + 2 (1) = µ + 2 s
Derfor: [8, 12] = [µ - 2s, µ + 2s]
I følge den empiriske regelen kan det fastslås at 68,27% av ett år gamle barn i landet har mellom 8 og 12 kilo vekt.
b) Hva er sannsynligheten for å finne et år gammelt barn som veier 7 kg eller mindre?
7 = 10 - 3 = 10 - 3 (1) = µ - 3 s
Det er kjent at 7 kg vekt representerer verdien µ - 3s, så vel som det er kjent at 99,73% av barna er mellom 7 og 13 kg vekt. Det etterlater bare 0,27% av det totale antallet ekstreme barn. Halvparten av dem, 0,355%, er 7 kg eller mindre, og den andre halvparten, 0,135%, er 11 kg eller mer.
Så det kan konkluderes med at det er en sannsynlighet på 0,00135 at et barn veier 7 kilo eller mindre.
c) Hvis landets befolkning når 50 millioner innbyggere og 1 år gamle barn representerer 1% av landets befolkning, hvor mange år gamle barn vil veie mellom 9 og 11 kilo?
9 = 10 - 1 = µ - s
11 = 10 + 1 = µ + s
Derfor: [9, 11] = [µ - s, µ + s]
I følge den empiriske regelen er 68,27% av ettåringene i landet i intervallet [µ - s, µ + s]
Det er 500 000 ettåringer i landet (1% av 50 millioner), så 341,350 barn (68,27% av 500 000) veier mellom 9 og 11 kg.


Ingen har kommentert denne artikkelen ennå.