De ikke-grupperte data er de som, hentet fra en studie, ennå ikke er organisert av klasser. Når det er et håndterbart antall data, vanligvis 20 eller mindre, og det er få forskjellige data, kan det behandles som ikke-gruppert og verdifull informasjon hentet fra den.
De ikke-grupperte dataene kommer som det er fra undersøkelsen eller studien som ble utført for å skaffe dem og mangler derfor behandling. La oss se på noen eksempler:

-Resultater av en IQ-test på 20 tilfeldige studenter fra et universitet. Dataene som ble innhentet var følgende:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112.106
-Aldere på 20 ansatte i en bestemt populær kaffebar:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
-Det endelige karaktergjennomsnittet på 10 studenter i en matematikktime:
3,2; 3.1; 2,4; 4,0; 3,5; 3,0; 3,5; 3,8; 4,2; 4.9
Artikkelindeks
Det er tre viktige egenskaper som kjennetegner et sett med statistiske data, enten de er gruppert eller ikke, som er:
-Posisjon, som er datatendensen til å gruppere seg rundt visse verdier.
-Spredning, en indikasjon på hvor spredt eller spredt dataene er rundt en gitt verdi.
-Form, Det refererer til måten dataene distribueres på, noe som verdsettes når en graf av den samme er konstruert. Det er veldig symmetriske kurver og også skjevt, enten til venstre eller til høyre for en viss sentral verdi.
For hver av disse egenskapene er det en rekke tiltak som beskriver dem. Når de er oppnådd, gir de oss en oversikt over oppførselen til dataene:
-De mest brukte posisjonsmålene er det aritmetiske gjennomsnittet eller ganske enkelt gjennomsnittet, medianen og modusen.
-Rekkevidde, varians og standardavvik brukes ofte i spredning, men de er ikke de eneste målingene for spredning..
-Og for å bestemme formen, sammenlignes middelverdien og medianen gjennom skjevhet, som du vil se snart.
-Det aritmetiske gjennomsnittet, også kjent som gjennomsnitt og betegnet som X, beregnes det som følger:
X = (x1 + xto + x3 +... Xn) / n
Hvor x1, xto,…. xn, er dataene og n er summen av dem. I summeringsnotasjon har vi:
-Median er verdien som vises midt i en ordnet datasekvens, så for å få den, er det nødvendig å bestille dataene først og fremst.
Hvis antall observasjoner er odde, er det ikke noe problem å finne midtpunktet til settet, men hvis vi har et jevnt antall data, blir de to sentrale dataene søkt og gjennomsnittet.
-Mote er den vanligste verdien som observeres i datasettet. Det eksisterer ikke alltid, siden det er mulig at ingen verdi gjentas oftere enn en annen. Det kan også være to data med samme frekvens, i så fall snakker vi om en bi-modal fordeling.
I motsetning til de to foregående målene, kan modusen brukes med kvalitative data.
La oss se hvordan disse posisjonsmålene beregnes med et eksempel:
Anta at vi vil bestemme det aritmetiske gjennomsnittet, medianen og modusen i eksemplet som ble foreslått i begynnelsen: alderen 20 ansatte i en kafeteria:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
De halv det beregnes ganske enkelt ved å legge til alle verdiene og dele med n = 20, som er totalt antall data. På denne måten:
X = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22,3 år.
For å finne median du må sortere datasettet først:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
Siden det er et jevnt antall data, blir de to sentrale dataene, uthevet med fet skrift, tatt og beregnet i gjennomsnitt. Fordi de begge er 22, er medianen 22 år.
Til slutt, mote Det er dataene som gjentas mest eller den som har større frekvens, dette er 22 år.
Rekkevidden er rett og slett forskjellen mellom den største og minste av dataene, og lar deg raskt sette pris på variasjonen i dataene. Men bortsett fra det er andre målinger av spredning som gir mer informasjon om distribusjonen av dataene..
Variansen er betegnet som s og beregnes ved uttrykket:
Så for å tolke resultatene riktig er standardavviket definert som kvadratroten til variansen, eller også kvasistandardavviket, som er kvadratroten til kvasivariansen:
Det er sammenligningen mellom gjennomsnittlig X og median Med:
-Hvis Med = betyr X: dataene er symmetriske.
-Når X> Med: skjev til høyre.
-Og hvis X < Med: los datos sesgan hacia la izquierda.
Finn gjennomsnitt, median, modus, rekkevidde, varians, standardavvik og skjevhet for resultatene av en IQ-test utført på 20 studenter fra et universitet:
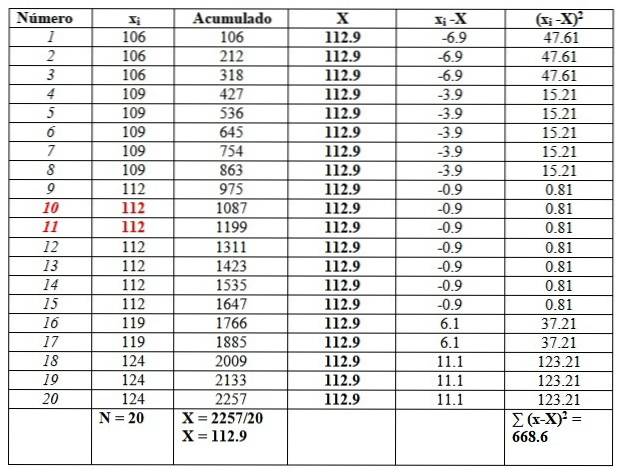
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
Vi vil bestille dataene, siden det vil være nødvendig å finne medianen.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 112, 119, 119, 124, 124, 124
Og vi vil sette dem i en tabell som følger, for å lette beregningene. Den andre kolonnen med tittelen "Akkumulert" er summen av tilsvarende data pluss den forrige..
Denne kolonnen hjelper deg med å enkelt finne gjennomsnittet, og deler den siste akkumulerte med det totale antall data, sett på slutten av kolonnen "Akkumulert":
X = 112,9
Medianen er gjennomsnittet av de sentrale dataene som er uthevet i rødt: tallet 10 og tallet 11. Siden de er de samme, er medianen 112.
Til slutt er modusen den verdien som gjentas mest og er 112, med 7 repetisjoner..
Når det gjelder målene for spredning, er rekkevidden:
124-106 = 18.
Avviket oppnås ved å dele det endelige resultatet i høyre kolonne med n:
s = 668,6 / 20 = 33,42
I dette tilfellet er standardavviket kvadratroten til variansen: √33.42 = 5.8.
På den annen side er verdiene til kvasi-variansen og kvasi-standardavviket:
sc= 668,6 / 19 = 35,2
Kva-standardavvik = √35.2 = 5.9
Til slutt er skjevheten litt til høyre, siden gjennomsnittet 112,9 er større enn medianen 112.



Ingen har kommentert denne artikkelen ennå.