
De Kumulativ frekvens er summen av de absolutte frekvensene f, fra den laveste til den som tilsvarer en viss verdi av variabelen. I sin tur er den absolutte frekvensen antall ganger en observasjon vises i datasettet.
Studievariabelen må åpenbart være sorterbar. Og siden den akkumulerte frekvensen oppnås ved å legge til de absolutte frekvensene, viser det seg at den akkumulerte frekvensen til de siste dataene, må sammenfalle med totalen av dem. Ellers er det feil i beregningene.

Vanligvis betegnes den kumulative frekvensen som FJeg (eller noen ganger nJeg), for å skille den fra den absolutte frekvensen fJeg og det er viktig å legge til en kolonne for den i tabellen som dataene er organisert med, kjent som frekvenstabell.
Dette gjør det blant annet lettere å holde oversikt over hvor mye data som ble telt opp til en viss observasjon..
A FJeg det er også kjent som absolutt kumulativ frekvens. Hvis vi deler den med de totale dataene, har vi relativ kumulativ frekvens, hvis endelige sum må være lik 1.
Artikkelindeks
Den kumulative frekvensen til en gitt verdi av variabelen XJeg er summen av de absolutte frekvensene f av alle verdier som er mindre enn eller lik den:
FJeg = f1 + Fto + F3 +... fJeg
Ved å legge til alle de absolutte frekvensene oppnås det totale antall data N, det vil si:
F1 + Fto + F3 +…. + Fn = N
Den forrige operasjonen er skrevet på en oppsummert måte ved hjelp av summeringssymbolet:
∑ FJeg = N
Følgende frekvenser kan også akkumuleres:
-Relativ frekvens: oppnås ved å dele den absolutte frekvensen fJeg mellom de totale dataene N:
Fr = fJeg / N
Hvis de relative frekvensene fra den laveste til den som tilsvarer en viss observasjon legges til, har vi kumulativ relativ frekvens. Den siste verdien må være lik 1.
-Prosentandel kumulativ relativ frekvens: den akkumulerte relative frekvensen multiplisert med 100%.
F% = (fJeg / N) x 100%
Disse frekvensene er nyttige for å beskrive oppførselen til dataene, for eksempel når man finner målene for sentral tendens.
For å oppnå den akkumulerte frekvensen er det nødvendig å bestille dataene og organisere dem i en frekvenstabell. Fremgangsmåten er illustrert i følgende praktiske situasjon:
-I en nettbutikk som selger mobiltelefoner, viste salgsrekorden for et bestemt merke for mars måned følgende verdier per dag:
1; to; 1; 3; 0; 1; 0; to; 4; to; 1; 0; 3; 3; 0; 1; to; 4; 1; to; 3; to; 3; 1; to; 4; to; 1; 5; 5; 3
Variabelen er antall solgte telefoner per dag og det er kvantitativt. Dataene som presenteres på denne måten er ikke så enkle å tolke, for eksempel kan eierne av butikken være interessert i å vite om det er noen trend, for eksempel ukedager når salget av det merket er høyere..
Informasjon som denne og mer kan fås ved å presentere dataene på en ryddig måte og spesifisere frekvensene..
For å beregne den kumulative frekvensen bestilles dataene først:
0; 0; 0; 0; 1; 1; 1; 1; 1; 1; 1; 1; to; to; to; to; to; to; to; to; 3; 3; 3; 3; 3; 3; 4; 4; 4; 5; 5
Deretter er det laget en tabell med følgende informasjon:
-Den første kolonnen til venstre med antall solgte telefoner, mellom 0 og 5 og i økende rekkefølge.
-Andre kolonne: absolutt frekvens, som er antall dager 0 telefoner, 1 telefon, 2 telefoner og så videre ble solgt.
-Tredje kolonne: den akkumulerte frekvensen, som består av summen av den forrige frekvensen pluss frekvensen av dataene som skal vurderes.
Denne kolonnen begynner med de første dataene i kolonnen for absolutt frekvens, i dette tilfellet er den 0. For neste verdi, legg til denne med den forrige. Det fortsetter slik til det når de siste dataene for den akkumulerte frekvensen, som må sammenfalle med de totale dataene.
Følgende tabell viser variabelen "antall solgte telefoner på en dag", dens absolutte frekvens og den detaljerte beregningen av den akkumulerte frekvensen.
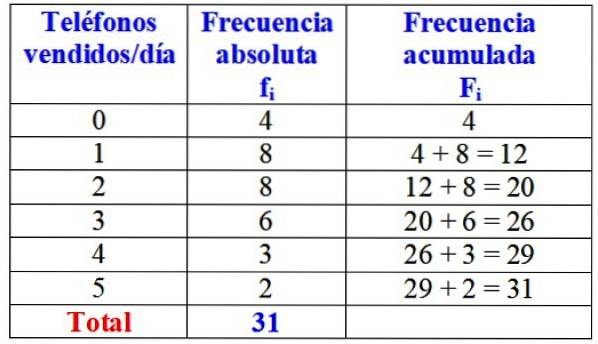
Ved en første øyekast kan det hevdes at av det aktuelle merket selges en eller to telefoner nesten alltid om dagen, siden den høyeste absolutte frekvensen er 8 dager, noe som tilsvarer disse verdiene til variabelen. Bare i løpet av 4 dager i måneden solgte de ikke en eneste telefon.
Som nevnt er tabellen lettere å undersøke enn de individuelle dataene som opprinnelig ble samlet inn.
En kumulativ frekvensfordeling er en tabell som viser de absolutte frekvensene, de kumulative frekvensene, de kumulative relative frekvensene og de kumulative prosentfrekvensene..
Selv om det er fordelen med å organisere dataene i en tabell som den forrige, hvis antall data er veldig stort, kan det hende det ikke er nok å organisere dem som vist ovenfor, for hvis det er mange frekvenser, blir det fortsatt vanskelig å tolke.
Problemet kan løses ved å bygge en frekvensfordeling med intervaller, en nyttig prosedyre når variabelen tar et stort antall verdier, eller hvis det er en kontinuerlig variabel.
Her er verdiene gruppert i intervaller med lik amplitude, kalt klasse. Klassene er preget av å ha:
-Klassegrense: er de ekstreme verdiene for hvert intervall, det er to, den øvre grensen og den nedre grensen. Generelt hører den øvre grensen ikke til intervallet, men til den neste, mens den nedre grensen hører hjemme.
-Klassemerke: er midtpunktet for hvert intervall, og blir tatt som den representative verdien av det.
-Klassebredde: Det beregnes ved å trekke verdien av de største og minste dataene (rekkevidden) og dele med antall klasser:
Klassebredde = Område / Antall klasser
Utdypingen av frekvensfordelingen er beskrevet nedenfor..
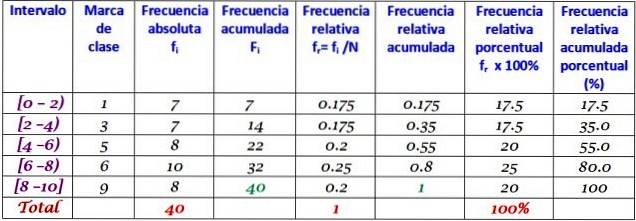
Dette datasettet tilsvarer 40 karakterer av en matematikkprøve, på en skala fra 0 til 10:
0; 0; 0; 1; 1; 1; 1; to; to; to; 3; 3; 3; 3; 4; 4; 4; 4; 5; 5; 5; 5; 6; 6; 6; 6; 7; 7; 7; 7; 7; 7; 8; 8; 8; 9; 9; 9; 10; 10.
En frekvensfordeling kan lages med et visst antall klasser, for eksempel 5 klasser. Det bør tas i betraktning at når du bruker mange klasser, er dataene ikke enkle å tolke, og følelsen av å gjennomføre grupperingen går tapt.
Og hvis de tvert imot er gruppert i veldig få, blir informasjonen utvannet og en del av den går tapt. Alt avhenger av mengden data du har.
I dette eksemplet er det en god ide å ha to score i hvert intervall, siden det er 10 poeng og 5 klasser vil bli opprettet. Området er subtraksjonen mellom høyeste og laveste karakter, og klassebredden er:
Klassebredde = (10-0) / 5 = 2
Intervallene er lukket til venstre og åpne til høyre (unntatt den siste), som er symbolisert med henholdsvis parentes og parentes. De har alle samme bredde, men det er ikke obligatorisk, selv om det ofte er.
Hvert intervall inneholder en viss mengde elementer eller absolutt frekvens, og i neste kolonne er den akkumulerte frekvensen der summen blir ført. Tabellen viser også den relative frekvensen fr (absolutt frekvens mellom det totale antallet data) og den prosentvise relative frekvensen fr × 100%.
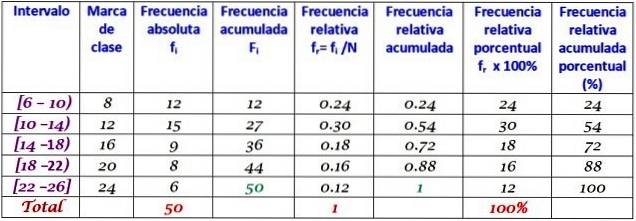
Ett selskap ringte daglig til sine kunder i løpet av de første to månedene av året. Dataene er som følger:
6, 12, 7, 15, 13, 18, 20, 25, 12, 10, 8, 13, 15, 6, 9, 18, 20, 24, 12, 7, 10, 11, 13, 9, 12, 15, 18, 20, 13, 17, 23, 25, 14, 18, 6, 14, 16, 9, 6, 10, 12, 20, 13, 17, 14, 26, 7, 12, 24, 7
Grupper i 5 klasser og bygg tabellen med frekvensfordeling.
Klassebredden er:
(26-6) / 5 = 4
Prøv å finne ut av det før du ser svaret.


Ingen har kommentert denne artikkelen ennå.