De hypergeometrisk fordeling er en diskret statistisk funksjon, egnet for å beregne sannsynligheten i randomiserte eksperimenter med to mulige utfall. Betingelsen som kreves for å bruke den er at de er små populasjoner der ekstraksjonene ikke erstattes og sannsynlighetene ikke er konstante..
Derfor, når et element av befolkningen velges for å kjenne resultatet (sant eller usant) av en viss egenskap, kan ikke det samme elementet velges igjen..

Det neste elementet som er valgt, er absolutt mer sannsynlig å oppnå et sant resultat hvis det forrige elementet hadde et negativt resultat. Dette betyr at sannsynligheten varierer når elementene blir hentet ut av prøven..
Hovedapplikasjonene til den hypergeometriske fordelingen er: kvalitetskontroll i prosesser med liten befolkning og beregning av sannsynligheter i sjansespill.
Når det gjelder den matematiske funksjonen som definerer den hypergeometriske fordelingen, består den av tre parametere, som er:
- Antall populasjonselementer (N)
- Prøvestørrelse (m)
- Antall hendelser i hele befolkningen med et gunstig (eller ugunstig) resultat av den studerte karakteristikken (n).
Artikkelindeks
Formelen for den hypergeometriske fordelingen gir sannsynligheten P om hva x gunstige tilfeller av en viss karakteristikk forekommer. Måten å skrive det matematisk på, basert på kombinasjonstallene, er:
I ovenstående uttrykk N, n Y m er parametere og x selve variabelen.
-Total befolkning er N.
-Antall positive resultater av en viss binær karakteristikk med hensyn til den totale befolkningen er n.
-Mengden prøveemner er m.
I dette tilfellet, X er en tilfeldig variabel som tar verdien x Y P (x) indikerer sannsynligheten for forekomst av x gunstige tilfeller av karakteristikken studert.
Andre statistiske variabler for den hypergeometriske fordelingen er:
- Halv μ = m * n / N
- Forskjell σ ^ 2 = m * (n / N) * (1-n / N) * (N-m) / (N-1)
- Typisk avvik σ som er kvadratroten til variansen.
For å komme fram til modellen for den hypergeometriske fordelingen, starter vi fra sannsynligheten for å oppnå x gunstige tilfeller i en prøvestørrelse m. Nevnte prøve inneholder elementer som samsvarer med egenskapen som studeres, og elementer som ikke gjør det.
Husk at n representerer antall gunstige tilfeller i den totale befolkningen på N elementer. Da blir sannsynligheten beregnet slik:
P (x) = (antall måter å få x # mislykkede måter) / (totalt antall måter å velge)
Når vi uttrykker det ovennevnte i form av kombinatoriske tall, kommer vi til følgende sannsynlighetsfordelingsmodell:
De er som følger:
- Utvalget må alltid være lite, selv om populasjonen er stor.
- Elementene i prøven ekstraheres en etter en uten å innlemme dem i populasjonen.
- Egenskapen som skal studeres er binær, det vil si at den bare kan ta to verdier: 1 eller 0, O vel sikker eller forfalskning.
I hvert elementutvinningstrinn endres sannsynligheten avhengig av de forrige resultatene.
En annen egenskap ved den hypergeometriske fordelingen er at den kan tilnærmes med binomialfordelingen, betegnet som Bi, så lenge befolkningen N er stor og minst 10 ganger større enn prøven m. I dette tilfellet vil det se slik ut:
P (N, n, m; x) = Bi (m, n / N, x)
Gjelder så lenge N er stor og N> 10m
Anta at en maskin som produserer skruer og de akkumulerte dataene indikerer at 1% kommer ut med feil. Så i en boks med N = 500 skruer vil antallet defekte være:
n = 500 * 1/100 = 5
Anta at fra den boksen (det vil si fra den befolkningen) tar vi et utvalg på m = 60 bolter.
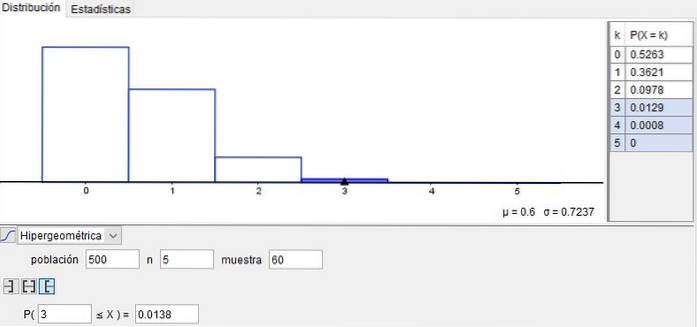
Sannsynligheten for at ingen skruer (x = 0) i prøven er defekt er 52,63%. Dette resultatet oppnås ved å bruke den hypergeometriske fordelingsfunksjonen:
P (500, 5, 60, 0) = 0,5263
Sannsynligheten for at x = 3 skruer i prøven er defekte er: P (500, 5, 60, 3) = 0,0129.
På den annen side er sannsynligheten for at x = 4 skruer på seksten av prøven er defekte: P (500, 5, 60; 4) = 0,0008.
Til slutt er sannsynligheten for at x = 5 skruer i prøven er defekt: P (500, 5, 60; 5) = 0.
Men hvis du vil vite sannsynligheten for at det i den prøven er mer enn tre defekte skruer, må du oppnå den kumulative sannsynligheten og legge til:
P (3) + P (4) + P (5) = 0,0129 + 0,0008 + 0 = 0,0137.
Dette eksemplet er illustrert i figur 2, oppnådd ved bruk av GeoGebra en gratis programvare som er mye brukt i skoler, institutter og universiteter.
En spansk kortstokk har 40 kort, hvorav 10 har gull og de resterende 30 ikke. Anta at 7 kort trekkes tilfeldig fra den kortstokken, som ikke blir reinkorporert i kortstokken.
Hvis X er antall gull som er tilstede i de 7 trekkede kortene, blir sannsynligheten for at det vil være x gull i en 7-korts trekning gitt av den hypergeometriske fordelingen P (40,10,7; x).
La oss se dette slik: for å beregne sannsynligheten for å ha 4 gull i en 7-korts tegning bruker vi formelen for den hypergeometriske fordelingen med følgende verdier:

Og resultatet er: 4,57% sannsynlighet.
Men hvis du vil vite sannsynligheten for å få mer enn fire kort, må du legge til:
P (4) + P (5) + P (6) + P (7) = 5,20%
Følgende sett med øvelser er ment å illustrere og assimilere konseptene som er presentert i denne artikkelen. Det er viktig at leseren prøver å løse dem på egenhånd, før han ser på løsningen.
En kondomfabrikk har funnet ut at av 1000 kondomer produsert av en bestemt maskin, 5 kommer ut defekte. For kvalitetskontroll tas 100 kondomer tilfeldig, og partiet avvises hvis det er minst en eller flere defekte. Svar:
a) Hva er muligheten for at mange 100 blir kastet?
b) Er dette kvalitetskontrollkriteriet effektivt??
I dette tilfellet vises veldig store kombinasjonstall. Beregning er vanskelig med mindre en passende programvarepakke er tilgjengelig.
Men siden det er en stor populasjon og utvalget er ti ganger mindre enn den totale befolkningen, er det mulig å bruke tilnærmingen av den hypergeometriske fordelingen ved binomialfordeling:
P (1000,5,100; x) = Bi (100, 5/1000, x) = Bi (100, 0,005, x) = C (100, x) * 0,005 ^ x (1-0,005) ^ (100-x)
I ovenstående uttrykk C (100, x) er et kombinasjonsnummer. Da blir sannsynligheten for at det er mer enn en mangel beregnet slik:
P (x> = 1) = 1 - Bi (0) = 1- 0.6058 = 0.3942
Det er en utmerket tilnærming, hvis den sammenlignes med verdien oppnådd ved å bruke den hypergeometriske fordelingen: 0,4102
Det kan sies at med 40% sannsynlighet bør en gruppe med 100 profylaktiske stoffer kastes, noe som ikke er veldig effektivt..
Men hvis vi er litt mindre krevende i kvalitetskontrollprosessen, og vi vil bare forkaste batchen på 100 hvis det er to eller flere mangler, vil sannsynligheten for å forkaste batchen falle til bare 8%..
En plastpluggmaskin fungerer på en slik måte at av hver tiende del kommer en deformert ut. I et utvalg på 5 stykker, hvor sannsynlig er det at bare ett stykke er defekt?.
Befolkning: N = 10
Antall n mangler for hver N: n = 1
Prøvestørrelse: m = 5
P (10, 1, 5; 1) = C (1,1) * C (9,4) / C (10,5) = 1 * 126/252 = 0,5
Derfor er det en 50% sannsynlighet for at i en prøve på 5 vil en signatur komme deformert ut.
I et møte med unge videregående studenter er det 7 damer og 6 herrer. Blant jentene studerer 4 humaniora og 3 naturfag. I guttegruppen studerer 1 humaniora og 5 naturvitenskap. Beregn følgende:
a) Velge tre jenter tilfeldig: hva er sannsynligheten for at de alle studerer humaniora?.
b) Hvis tre deltakere på vennemøtet velges tilfeldig: Hva er muligheten for at tre av dem, uavhengig av kjønn, studerer naturvitenskap alle tre, eller humaniora også alle tre?.
c) Velg nå to venner tilfeldig og ring x til den tilfeldige variabelen "antall av dem som studerer humaniora". Bestem middelverdien eller forventet verdi mellom de to valgte x og variansen σ ^ 2.
Befolkningen er det totale antallet jenter: N = 7. De som studerer humaniora er n = 4, av totalen. Det tilfeldige utvalget av jenter vil være m = 3.
I dette tilfellet er sannsynligheten for at alle tre er humanistiske studenter gitt av den hypergeometriske funksjonen:
P (N = 7, n = 4, m = 3, x = 3) = C (4, 3) C (3, 0) / C (7, 3) = 0,1143
Så det er 11,4% sannsynlighet for at tre jenter tilfeldig valgt vil studere humaniora..
Verdiene som skal brukes nå er:
-Befolkning: N = 14
-Mengden som studerer bokstaver er: n = 6 og
-Prøvestørrelse: m = 3.
-Antall venner som studerer humaniora: x
I følge dette betyr x = 3 at alle tre studerer humaniora, men x = 0 betyr at ingen studerer humaniora. Sannsynligheten for at alle tre studerer det samme er gitt av summen:
P (14, 6, 3, x = 0) + P (14, 6, 3, x = 3) = 0,0560 + 0,1539 = 0,2099
Så har vi en 21% sannsynlighet for at tre møtedeltakere, valgt tilfeldig, vil studere det samme.
Her har vi følgende verdier:
N = 14 total populasjon av venner, n = 6 totalt antall i befolkningen som studerer humaniora, utvalgsstørrelsen er m = 2.
Håpet er:
E (x) = m * (n / N) = 2 * (6/14) = 0,8572
Og avviket:
σ (x) ^ 2 = m * (n / N) * (1-n / N) * (Nm) / (N-1) = 2 * (6/14) * (1-6 / 14) * (14-2) / (14 -1) =
= 2 * (6/14) * (1-6 / 14) * (14-2) / (14-1) = 2 * (3/7) * (1-3 / 7) * (12) / (13 ) = 0,4521

Ingen har kommentert denne artikkelen ennå.