De målinger av variabilitet, Også kalt måling av spredning, de er statistiske indikatorer som indikerer hvor nær eller langt dataene er fra det aritmetiske gjennomsnittet. Hvis dataene er nær gjennomsnittet, er fordelingen konsentrert, og hvis de er langt borte, er det en sparsom fordeling..
Det er mange målinger av variabilitet, blant de mest kjente er:
Disse tiltakene utfyller målene for sentral tendens og er nødvendige for å forstå fordelingen av innhentede data og trekke ut så mye informasjon fra dem..
Område eller spennmål måler bredden til et datasett. For å bestemme verdien, er forskjellen mellom dataene med den høyeste verdien xmaks og den med den laveste verdien xmin:
R = xmaks - xmin
Hvis dataene ikke er løse, men gruppert etter intervall, beregnes rekkevidden av forskjellen mellom den øvre grensen for det siste intervallet og den nedre grensen for det første intervallet.
Når rekkevidden er en liten verdi, betyr det at alle dataene ligger ganske nær hverandre, men et stort område indikerer at det er mye variasjon. Det er klart at bortsett fra den øvre og nedre grensen for dataene, tar ikke rekkevidden hensyn til verdiene mellom dem, så det anbefales ikke å bruke det når antall data er stort.
Imidlertid er det et øyeblikkelig mål å beregne og har de samme enhetene av dataene, så det er lett å tolke.
Nedenfor er listen med antall scorede mål i løpet av helgen, i fotballigaene i ni land:
40, 32, 35, 36, 37, 31, 37, 29, 39
Dette er et ikke-gruppert datasett. For å finne rekkevidden fortsetter vi med å bestille dem fra laveste til høyeste:
29, 31, 32, 35, 36, 37, 37, 39, 40
Dataene med høyest verdi er 40 mål og den med laveste verdi er 29 mål, og derfor er rekkevidden:
R = 40−29 = 11 mål.
Det kan ansees at området er lite sammenlignet med minimumsverdidataene, som er 29 mål, så det kan antas at dataene ikke har stor variasjon.
Dette måling av variabilitet beregnes gjennom gjennomsnittet av de absolutte verdiene til avvikene i forhold til gjennomsnittet.. Betegner middelavviket som DM, For ikke-grupperte data beregnes gjennomsnittlig avvik med følgende formel:
Hvor n er antall tilgjengelige data, xJeg representerer hver data og x̄ er gjennomsnittet, som bestemmes ved å legge til alle data og dele med n:
Gjennomsnittlig avvik gjør det mulig å vite i gjennomsnitt hvor mange enheter dataene avviker fra det aritmetiske gjennomsnittet og har fordelen av å ha de samme enhetene som dataene vi jobber med.
Basert på dataene fra rekkeviddeeksemplet er antall scorede mål:
40, 32, 35, 36, 37, 31, 37, 29, 39
Hvis du vil finne middelavviket DM Fra disse dataene er det nødvendig å beregne det aritmetiske gjennomsnittet x̄:

Og nå som verdien av x̄ er kjent, fortsetter vi med å finne middelavviket DM:
= 2,99 ≈ 3 mål
Derfor kan det fastslås at dataene i gjennomsnitt er omtrent 3 mål unna gjennomsnittet, som er 35 mål, og som nevnt er det et mye mer presist mål enn rekkevidden..
Gjennomsnittlig avvik er et mye finere mål på variabilitet enn området, men siden det beregnes gjennom den absolutte verdien av forskjellene mellom hver data og gjennomsnittet, gir det ikke større allsidighet fra et algebraisk synspunkt..
Av denne grunn foretrekkes variansen, som tilsvarer gjennomsnittet av den kvadratiske forskjellen mellom hver data og gjennomsnittet og beregnes ved hjelp av formelen:
I dette uttrykket, sto betegner variansen, og som alltid xJeg representerer hver av dataene, x̄ er gjennomsnittet og n er den totale data.
Når du arbeider med et utvalg i stedet for populasjonen, foretrekkes det å beregne avviket slik:
I alle fall er variansen preget av å alltid være en positiv størrelse, men siden det er gjennomsnittet av kvadratiske forskjeller, er det viktig å merke seg at den ikke har de samme enhetene som dataene..
For å beregne avviket til dataene i eksemplene på rekkevidde og gjennomsnittlig avvik, fortsetter vi med å erstatte de tilsvarende verdiene og utføre den angitte summeringen. I dette tilfellet velger vi å dele med n-1:

= 13,86
Avviket har ikke samme enhet som variabelen som studeres, for eksempel, hvis dataene kommer i meter, resulterer avviket i kvadratmeter. Eller i måleksemplet vil det være i mål i kvadrat, noe som ikke gir mening.
Derfor er standardavviket definert, også kalt typisk avvik, som kvadratroten til variansen:
s = √sto
På denne måten oppnås et mål på variabilitet av dataene i de samme enhetene som disse, og jo lavere verdien av s er, desto mer gruppert er dataene rundt gjennomsnittet..
Både variansen og standardavviket er målene for variabilitet å velge når det aritmetiske gjennomsnittet er målet for sentral tendens som best beskriver oppførselen til dataene..
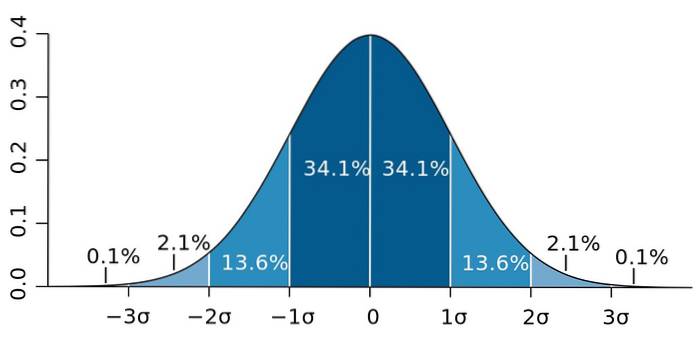
Og det er at standardavviket har en viktig egenskap, kjent som Chebyshevs teorem: minst 75% av observasjonene er i intervallet definert av x̄ ± 2s. Med andre ord, 75% av dataene er maksimalt 2s unna gjennomsnittet..
På samme måte er minst 89% av verdiene i en avstand på 3s fra gjennomsnittet, en prosentandel som kan utvides, så lenge det er mye data tilgjengelig og de følger en normalfordeling..
Figur 2. - Hvis dataene følger en normalfordeling, ligger 95,4 av dem innenfor to standardavvik på begge sider av gjennomsnittet. Kilde: Wikimedia Commons.
Standardavviket til dataene som er presentert i de foregående eksemplene er:
s = √sto = √13,86 = 3,7 ≈ 4 mål



Ingen har kommentert denne artikkelen ennå.